SimpleDB (Part 2): Memory Management
Contents
(Note: This post is part of the SimpleDB series. Please check the first post if you haven’t already)
Intro
Accessing data from disk is dramatically slower than from RAM - by a factor of 100,000. That’s why memory management matters.
For any data processing task, it’s the rate limiting factor.
In this post we’ll focus on implementing key parts of the BufferManager to show how it helps minimize disk access. For the full implementation, see this branch.
How does a DB engine try to minimize disk access? When a client requests data, the goal is for it to already be in memory, bypassing the slow disk retrieval.
This sounds like a cache!
Buffer: Your DB’s memory
In SimpleDB, we’re going to implement a buffer to hold the content of a block in memory. It also contains information like if the buffer is pinned, what block it is assigned to, etc.
But first, let’s look at the struct of our buffer.
pub struct BufferPage { fm: Arc<FileManager>, lm: Arc<Mutex<LogManager>>, contents: Page, block: Option<BlockId>, pins: u32, txnum: i32, lsn: i32,}The main things to see here are contents which contains the page’s data, and block which is a reference to the BlockId. pins refers to if the buffer’s contents are currently in used by any client. We will use txnum and lsn in later chapter when handling transaction management.
Now that we understand the structure of the buffer, what should it do?
If it holds page contents in memory, what happens if a client needs to make changes to the page? Clients change page contents, prompting a write to disk for permanence. But our goal is to minimize disk access, which includes disk writes.
Our buffer strategy to minimize disk writes involves only two scenarios where we would write to disk:
- when the page is getting replaced because the buffer is getting pinned to another block
- when the recovery manager needs to write the page to disk to guard against possible system crash
We’ll look at two important functions for the buffer, which are really read and write.
First, assign_to_block, which reads the contents of the specified block into the contents of the buffer.
impl BufferPage { # ... pub fn assign_to_block(&mut self, b: BlockId) -> std::io::Result<()> { self.flush()?; self.block = Some(b.clone()); self.fm.read(&b, &mut self.contents)?; self.pins = 0; Ok(()) } # ...}Notice how we first flush the existing data. If the buffer had existing page content and it was already modified (dirty), then it needs to be written to disk before it gets assigned a new page.
Once the existing page is flushed to disk, then it will take a new block, and read its contents into the buffer.
Now let’s look at flush.
impl BufferPage { # ... pub fn flush(&mut self) -> std::io::Result<()> { if self.txnum >= 0 { self.lm.lock().unwrap().flush(self.lsn)?; if let Some(block) = &self.block { self.fm.write(block, &mut self.contents)?; } self.txnum = -1; } Ok(()) } # ...}- First, we check
self.txnum >= 0. This is our way of indicating if the buffer is involved in a transaction and has modified content - If there is a a block in the buffer, we have the file manager write our buffer’s contents to the block on disk
- Finally, we change the buffer’s
txnumto -1 to indicate that our buffer has already been written to disk
For the full implementation of BufferPage and tests, see this.
With our buffer implementation complete, we need a way to manage multiple buffers efficiently. This is where the buffer manager comes in.
Buffer Management strategies
The buffer manager organizes a pool of buffers where some buffers might be pinned (in use by a client) or unpinned (free to take).
When a client requests data from the buffer manager, let’s see what might happen:
- contents of the block are in a buffer
- page is pinned
- page is unpinned
- contents of the block are not in the buffer
- all buffers in the buffer pool are pinned (client is put on wait list)
- there exists at least one unpinned buffer in the buffer pool
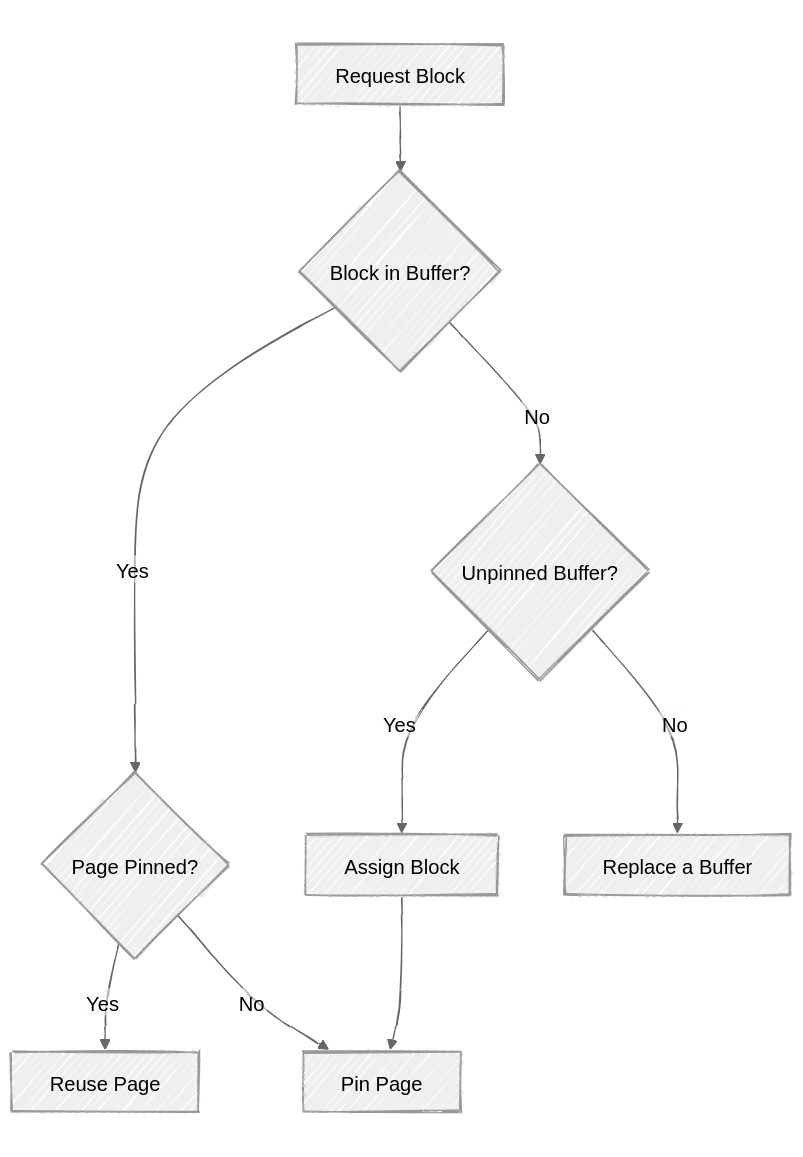
If the contents of the block are in a buffer, then it’s simple. We can just reuse the page.
If the contents of the block are not in the buffer and there’s at least one unpinned buffer in the pool, then we can use that buffer and pin it with our block.
So that means the only complicated scenario is when all the buffers in the pool are pinned. If they are all pinned, we need to choose a buffer to replace.
There are 4 potential replacement strategies:
- naive
- Choose the first unpinned buffer. But then you run into the problem of not evenly using the buffer pool.
- FIFO (first in first out)
- Choose the buffer that has been in the pool the longest (oldest ‘add’ time). The problem with this is that frequently used buffers are often among the ones that are in the pool longest.
- LRU (least recently used)
- Choose the buffer that has not been used for the longest period. This is an effective general strategy since it avoids replacing commonly used pages.
- clock:
- Starts scanning at the page after the previous replacement, and chooses the first unpinned page it finds. Attempts to use the buffers as evenly as possible. Since frequently used buffers will usually be pinned, it has a higher chance of skipping over those.
Let’s move onto the implementation. First, we’ll define the struct.
pub struct BufferManager { buffer_pool: Vec<Arc<Mutex<BufferPage>>>, num_available: Mutex<usize>, max_time: u64,}Our buffer_pool is a vector of buffers. num_available refers to the number of buffers that are unpinned. And max_time refers to how long a client will have to wait for an available buffer before receiving an error.
As for the most important functions for the BufferManager, they are pin and unpin.
pin will pin a buffer to the specified block, potentially waiting max_time until a buffer becomes available. If no buffer is available after that time period, then an error is thrown.
impl BufferManager { # ... pub fn pin(&self, block: BlockId) -> Result<Arc<Mutex<BufferPage>>, BufferError> { let deadline = Instant::now() + Duration::from_millis(self.max_time);
while Instant::now() < deadline { if let Ok(Some(buffer)) = self.try_to_pin(block.clone()) { return Ok(buffer); } std::thread::sleep(Duration::from_millis(10)); }
Err(BufferError("Could not pin buffer: timeout".into())) } # ...}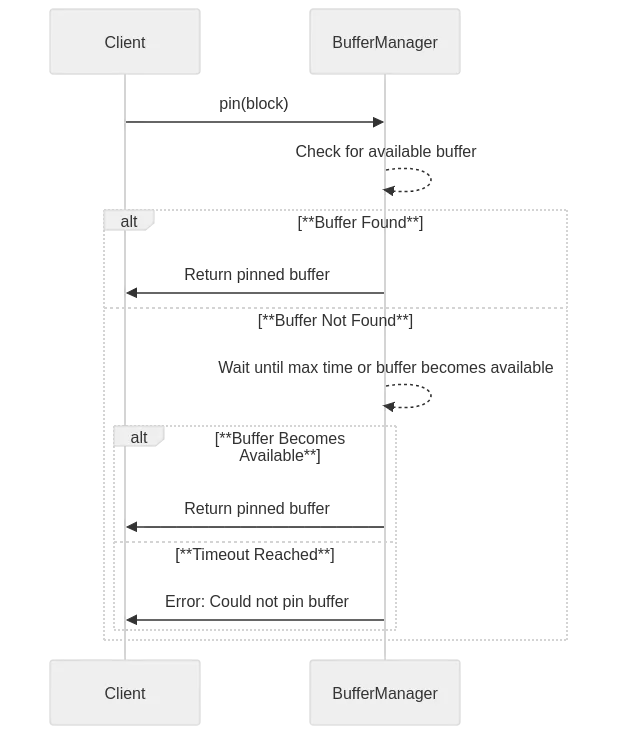
try_to_pin will pin a buffer to the specified block. But if there’s already a buffer assigned to the block, then that buffer is used. Otherwise, it’ll try to choose an unpinned buffer.
impl BufferManager { # ... fn try_to_pin(&self, block: BlockId) -> Result<Option<Arc<Mutex<BufferPage>>>, std::io::Error> { if let Some(buff) = self.find_existing_buffer(&block) { let mut buffer = buff.lock().unwrap(); if !buffer.is_pinned() { let mut num_available = self.num_available.lock().unwrap(); *num_available -= 1; } buffer.pin(); return Ok(Some(buff.clone())); }
if let Some(buff) = self.choose_unpinned_buffer() { let mut buffer = buff.lock().unwrap(); buffer.assign_to_block(block)?; let mut num_available = self.num_available.lock().unwrap(); *num_available -= 1; buffer.pin(); Ok(Some(buff.clone())) } else { Ok(None) } } # ...}choose_unpinned_buffer is where we define the replacement strategy. As mentioned above, there are 4 we could potentially use. For SimpleDB, we’ll go with the naive approach.
impl BufferManager { # ... fn choose_unpinned_buffer(&self) -> Option<Arc<Mutex<BufferPage>>> { self.buffer_pool .iter() .find(|buff| { let buffer = buff.lock().unwrap(); !buffer.is_pinned() }) .cloned() }
}This simply looks for the first unpinned buffer (which does not evenly use all the buffers in the pool).
Finally, we’re going to implement unpin.
impl BufferManager { # ... pub fn unpin(&mut self, buffer: Arc<Mutex<BufferPage>>) { let mut buffer = buffer.lock().unwrap(); buffer.unpin();
if !buffer.is_pinned() { let mut num_available = self.num_available.lock().unwrap(); *num_available += 1; } }}It’ll call the unpin function on buffer, which decrements the pin count. If the buffer’s pin count goes to 0, it means that there are no active clients using that buffer. If that’s the case, we can increment the number of available buffers by 1. This function shows the clear relationship between the number of available/unpinned buffers and the action of unpinning.
With these two functions implemented, pin and unpin, we’ve got the basics down for our buffer manager.
For the full implementation and tests, see this.
Summary
In this second part of our SimpleDB series, we looked at memory management, specifically focusing on minimizing disk access. We implemented two main components: the buffer and the buffer manager.
The buffer holds block content in memory and handles page operations. We made it minimize disk writes only when necessary: during page replacement or when the recovery manager requires it.
The buffer manager handles a pool of buffers and the complex logic around buffer replacement and pinning. We implemented two crucial functions: pin and unpin.
If you’d like to see the full implementation along with the tests, visit the repo here.
Have some thoughts on this post? Reply with an email.