Evolution of RAG: Addressing the common problems of a simple RAG system
Contents
Have you implemented a simple RAG system but found it a bit lacking? Wasn’t sure how to approach improving it? In this post I’ll share some effective ways to improving a RAG system.
What does a simple RAG system look like?
If you’re familiar with RAG, feel free to skip to the next section. Here we’ll go over some of the main concepts to get on the same page.
The purpose of RAG is to give the LLM some external knowledge that it might not have, or that you want it to specifically have.
The main steps of a RAG system involve:
- Getting the user query
- Transforming the user query into a vector
- Doing a vector search between the query and your database of embeddings
- Retrieve the top
kchunks from your database that are closest to the user’s query - Combine the text in the top
kchunks and the user’s question into a single prompt for the LLM - Generate an answer from the LLM using this prompt.
The diagram below is a very simple example of what the flow looks like.
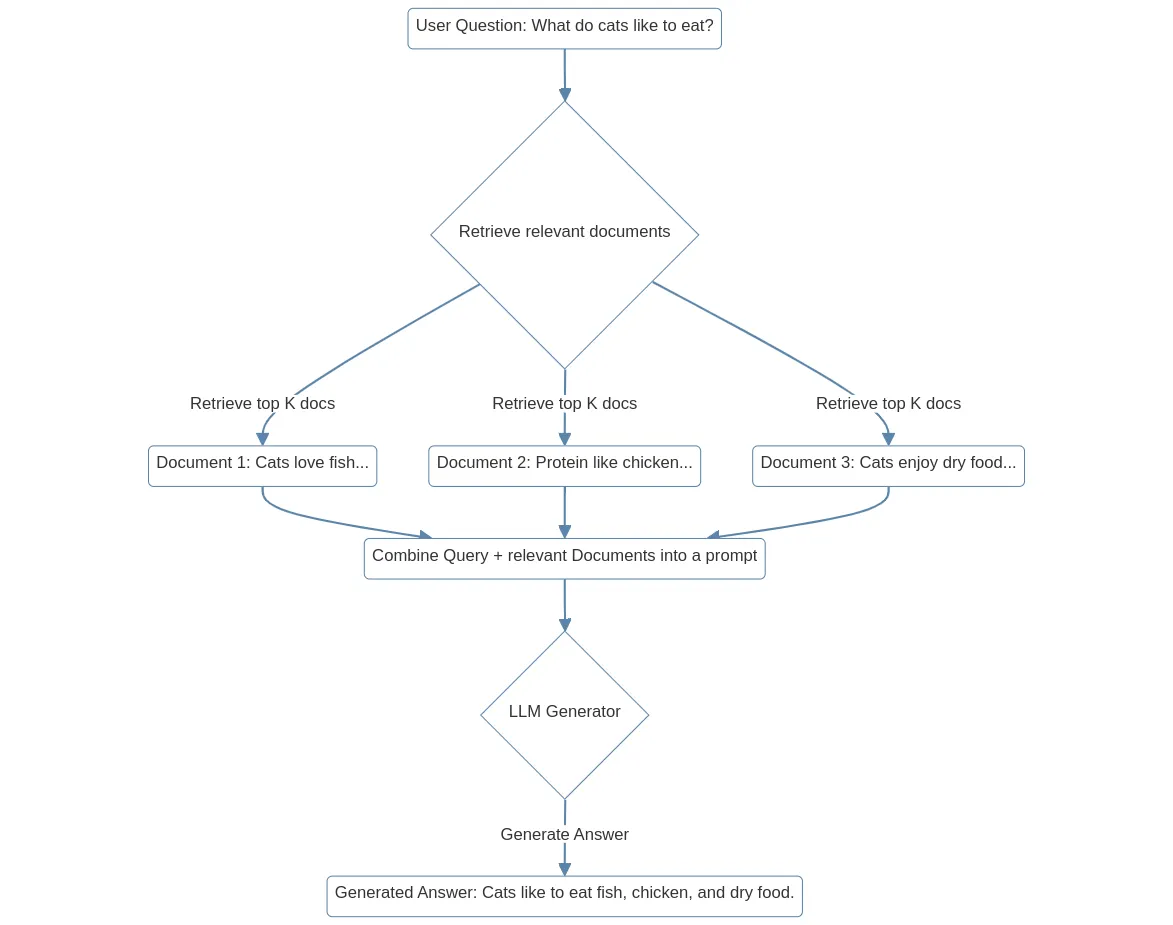
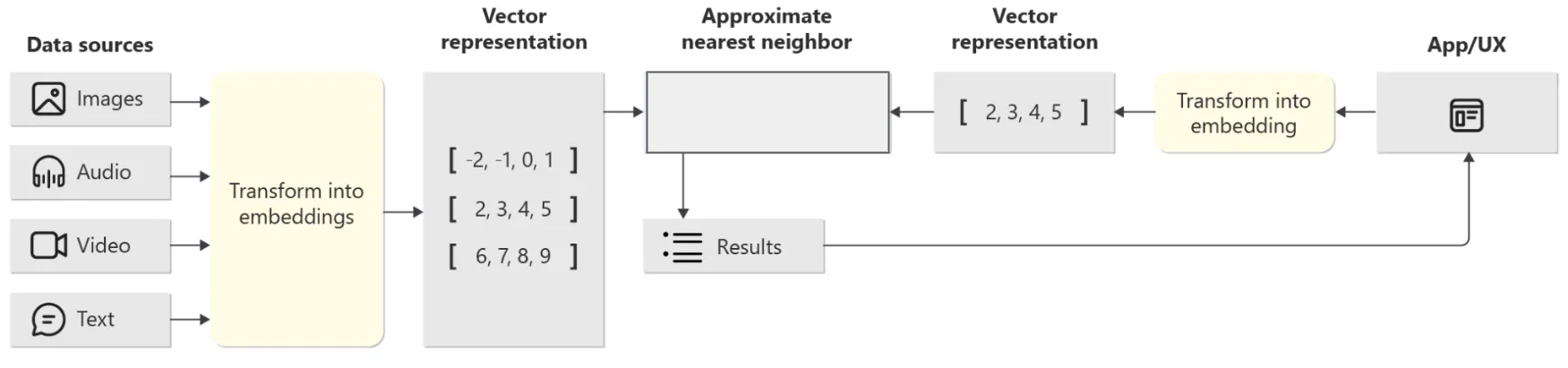
Where does these embeddings come from? They come from the data source that you want to search against. After transforming all your data sources into vector representations in your database, you would perform a nearest neighbour search between all those document embeddings and the vector of the query.
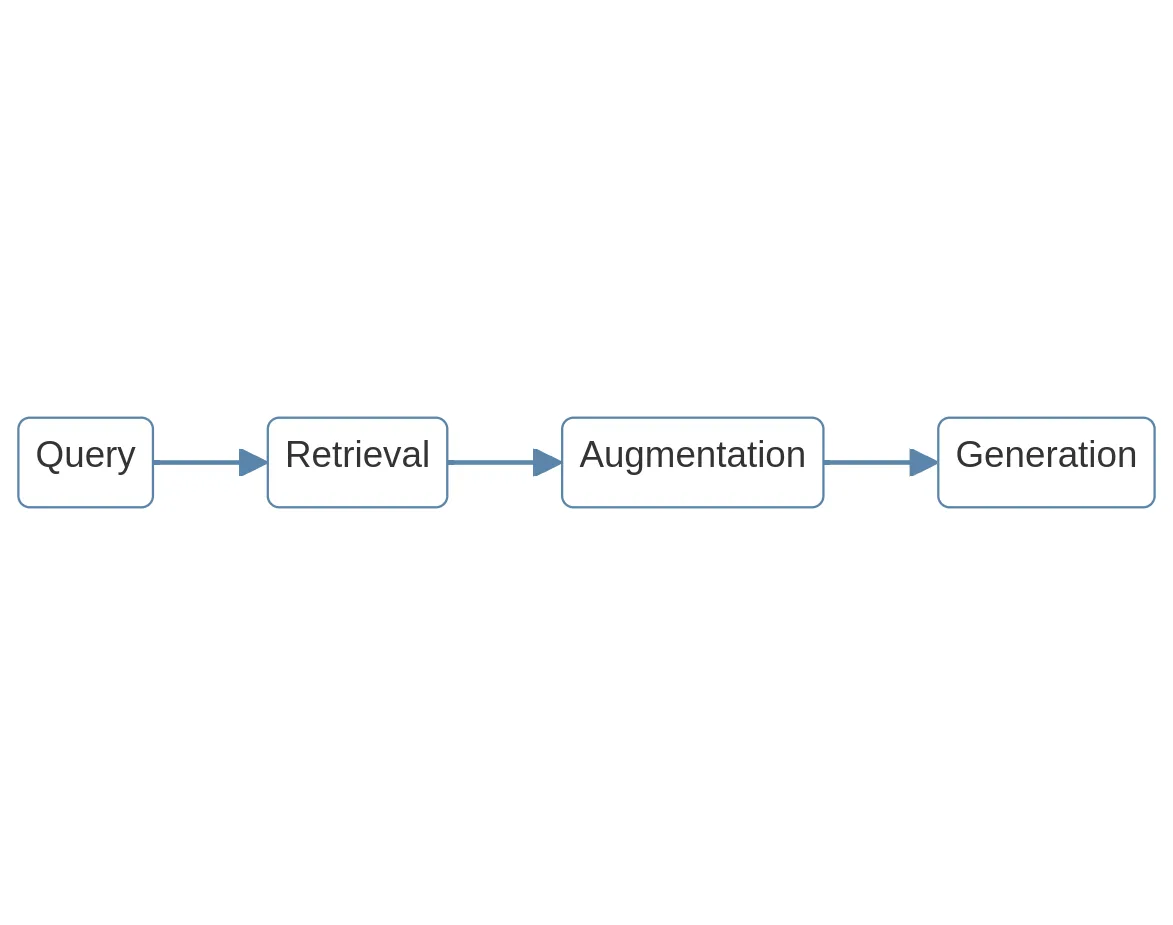
Main components of RAG
We can think of RAG as having these main components:
- Query
- Retrieval
- Augmentation
- Generation
Problems in RAG
After implementing a simple RAG system, you might encounter some common problems. We’ll split up these problems based on the components mentioned above.
Problems in the Query
- The user’s query might be unclear and require more context.
- eg. “I want to learn more about Java”. is that the programming language or coffee?
- Multi-faceted queries may indicate different intentions.
- eg. If a user asks about biochemistry and law, they may want to have two separate searches rather than one.
- Query understanding is very important and it’s not just about semantic similarity.
- eg. “between January and March”. The user clearly wants a date filter applied on the documents, and does not want documents that contain these phrases.
Problems in Retrieval
- Did not retrieve all the relevant documents (low recall)
- eg. if there are 10 relevant documents, and the system only found 5 of them
- The retrieved documents are not all relevant (low precision)
- eg. retrieved 10 documents but only 3 are relevant
- Outdated information
Problems in Augmentation and Generation
When you combine the user’s query and many document chunkcs together, you have super long context. This can lead to problems such as:
- “lost in the middle” problem (Liu et al., 2023a), when context in the middle of the prompt is ‘forgotten’ by the LLM
- redundancy and repetition concerns
- parroting retrieved content
- too much noise
- insufficient space for reasoning
Improving RAG with a modular approach
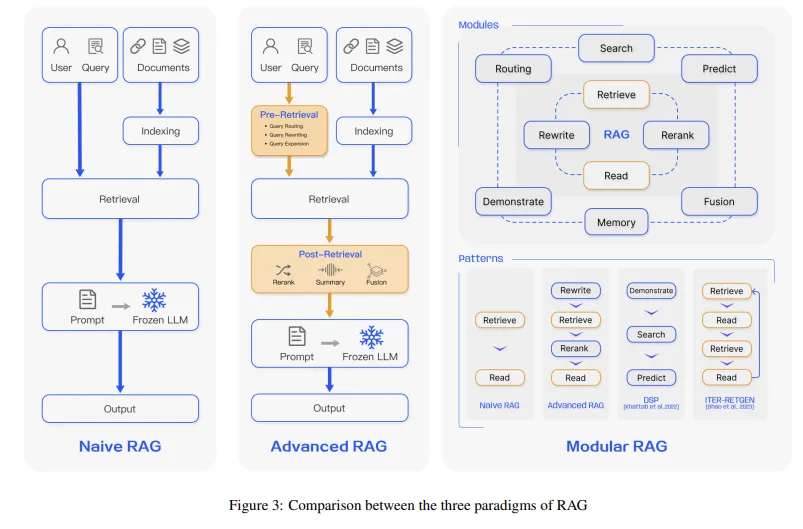
To improve these problems of RAG, we can take a modular approach. By considering each component of RAG as a module, and potentially made of different submodules, it will become easy to swap out different techniques depending on what works best for your case.
Improving the Query
The goal here is to improve the alignment of the semantic space between the query and the documents. There are a few interesting strategies around this.
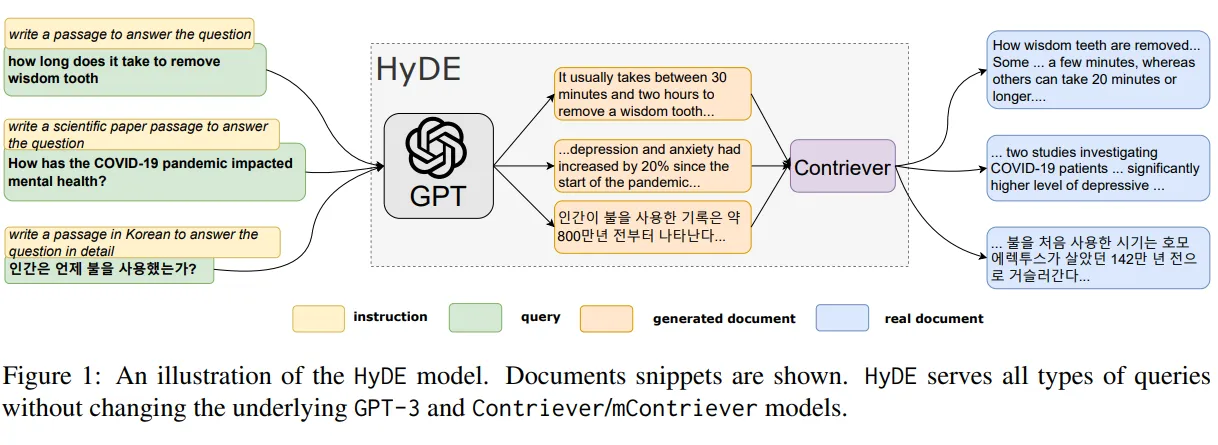
One is called HyDE, Hypothetical Document Embeddings (Gao et al. 2022). It works using an LLM to generate a hypothetical document for the query. This hypothetical document and the query are turned to embeddings and used during the retrieval stage. The intuition here is that it provides more information and context around the query, and make it more similar to existing real documents in the database.
There are many other strategies that have to do with query rewriting. One important one has to do with query understanding. In a previous example, we noted that a query with “between January and March” has the intention of using a filter, rather than trying to match documents that have this specific text.
Here is an example using the instructor lib to optimize a query. In these two models, DateRange and Query, we list how we want the query to be structured. It is passed to OpenAI’s response_model to generate a formatted query.
class DateRange(BaseModel): start: datetime.date end: datetime.date
class Query(BaseModel): rewritten_query: str published_daterange: DateRange domains_allow_list: List[str]
async def execute(): return await search(...)import instructorfrom openai import OpenAI
# Enables response_model in the openai clientclient = instructor.patch(OpenAI())
query = client.chat.completions.create( model="gpt-4", response_model=Query, messages=[ { "role": "system", "content": "You're a query understanding system for the search engine. Here are some tips: ..." }, { "role": "user", "content": "What are some recent developments in AI?" } ],)This is how the example query gets rewritten. You can see that there is a published_daterange that is formated very nicely and can be used in a filter function. This captures the user intention much better.
{ "rewritten_query": "novel developments advancements ai artificial intelligence machine learning", "published_daterange": { "start": "2023-09-17", "end": "2021-06-17" }, "domains_allow_list": ["arxiv.org"]}Another way to improve the query is to add metadata. If there is existing user information that is relevant to the query, it would be worthwhile to include it.
Improving the Retrieval Process
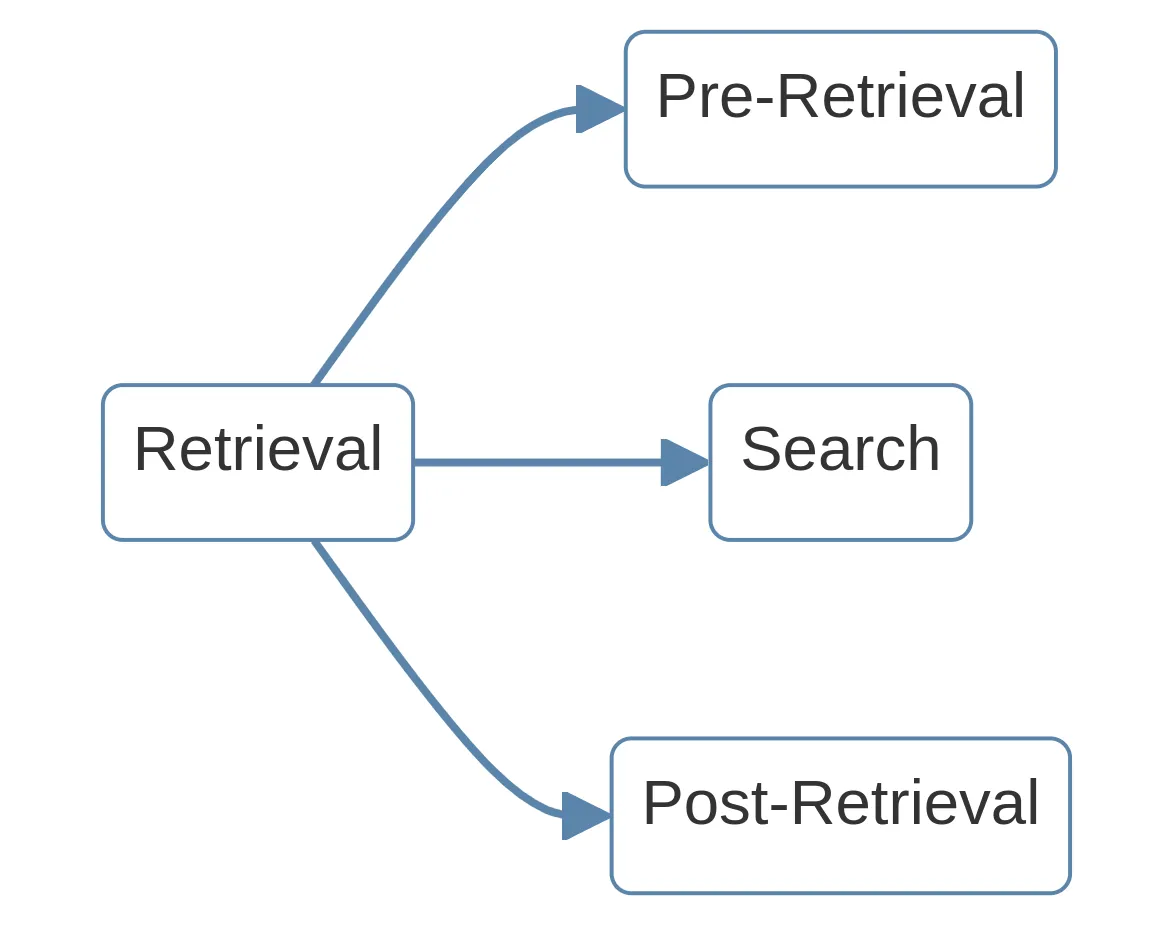
The retrieval process can be split up into 3 stages:
- pre-retrieval
- search
- post-retrieval
Pre-Retrieval
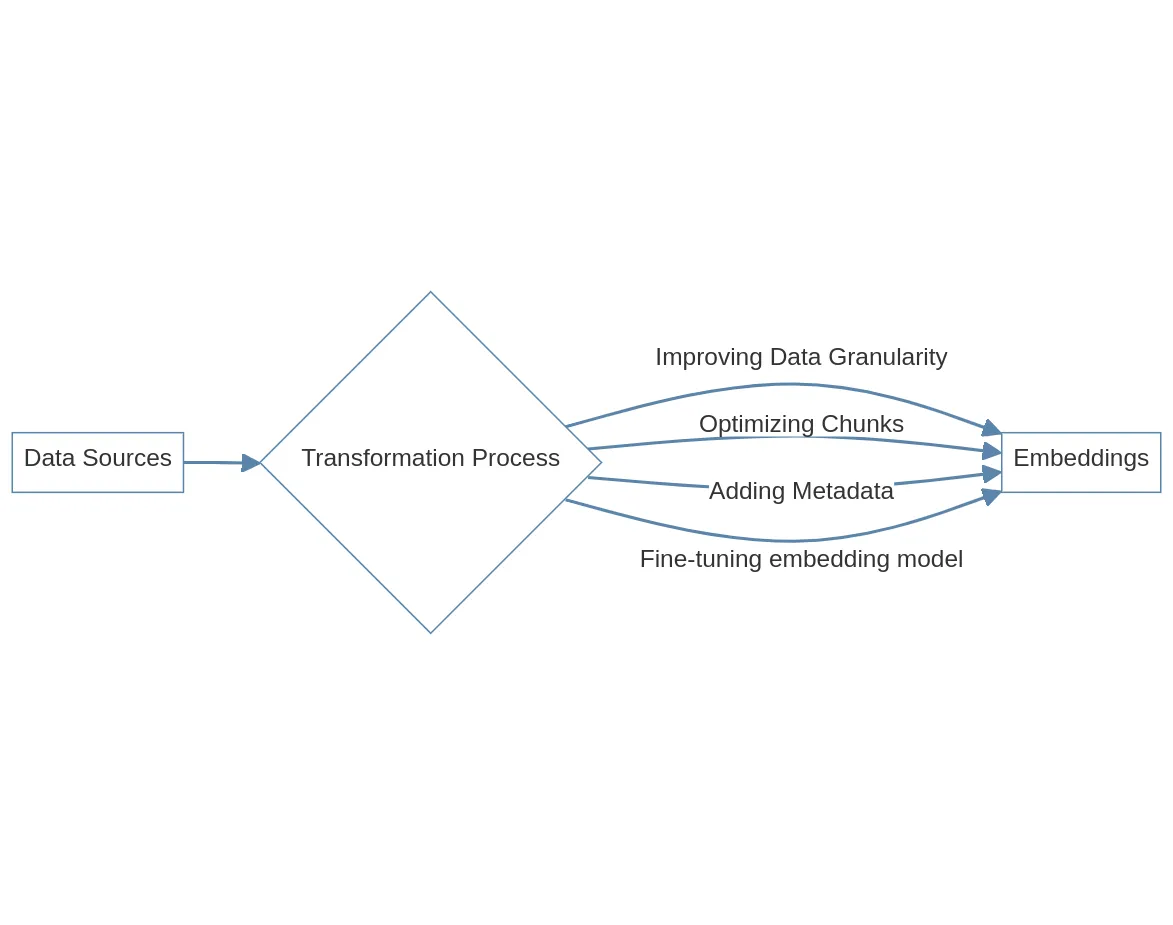
The purpose of improving this stage is to optimize the process of turning the data sources into embeddings.
The most important way here is likely to optimize chunks. The simple way of chunking data sources is to simply have a hard cutoff point, eg. N tokens if N is the embedding model’s limit.
An advanced chunking strategy is the small2big method. For each chunk, you use a small text chunk to represent it. For example, if you are indexing scientific papers, there are often abstracts that summarize each paper. The abstract will be used in the vector search instead of the full paper.
The choice of embedding model can also be considered. There are some embedding models that have different ideal chunk sizes (see this article about the how chunk size matters). Also, if your domain is relatively new or obscure, fine-tuning the embedding model will also provide benefits.
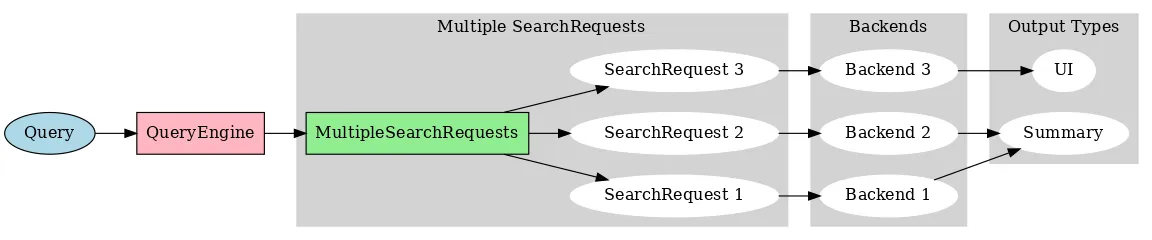
Search
In the search process, you may want to have a router that determines the appropriate type of search request for the query. For example, one search request could be for a vector database backend, and another request could be for a lexical search backend. Or they could be different filters for a backend, etc.
The point of having a query engine is to ensure that there is a ‘query understanding’ step that routes the query to the appropriate search request and backend.
Post-Retrieval
After you’ve retrieved the relevant top k chunks, another useful step to take is reranking.
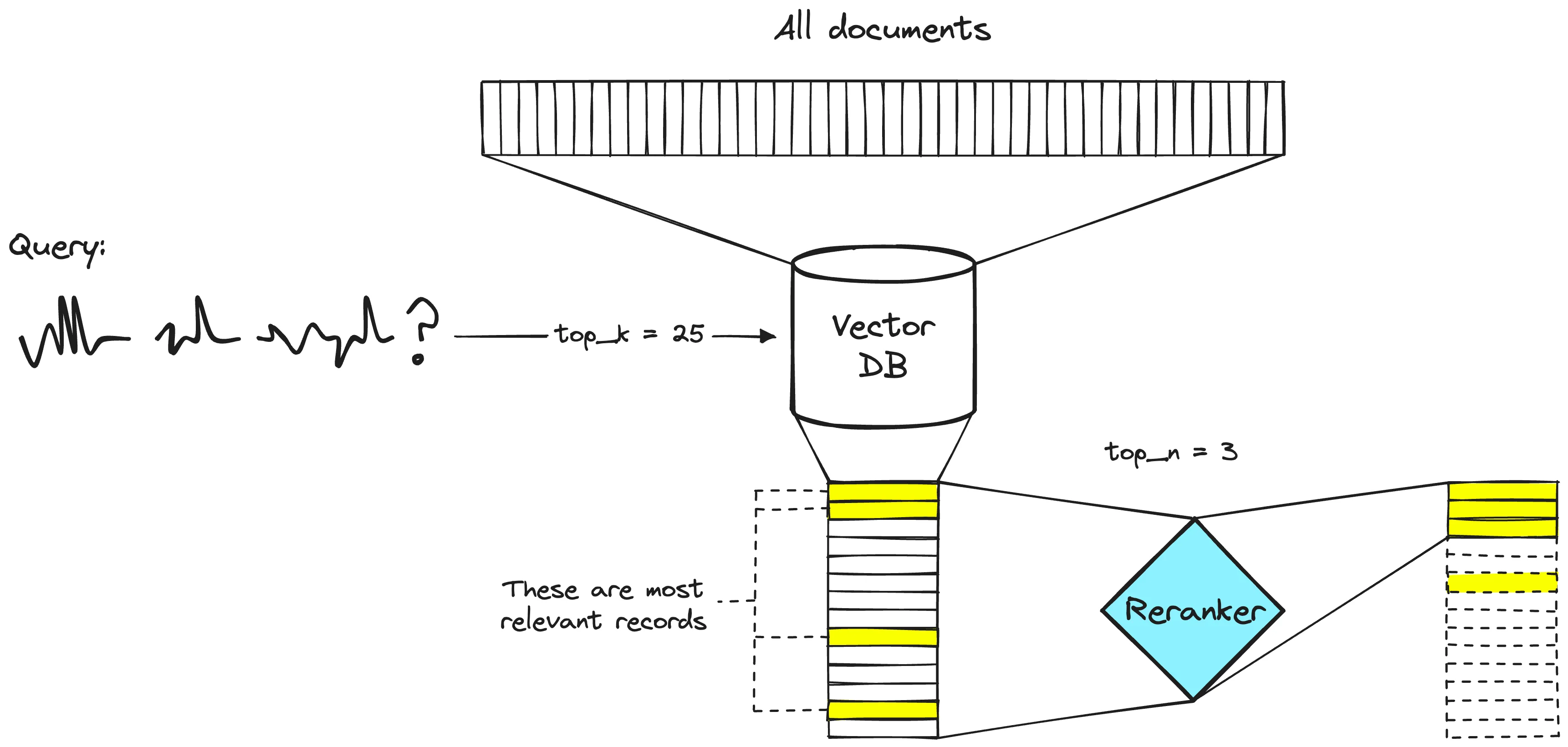
The reranker algorithm is usually a more intensive process (more accurate than embedding model), and that’s why you would only want to run it through a small sample. Some popular reranker algorithms include Cohere Rerank and BGE-rerank.
To deal with the large amount of context, one option is to compress the prompt. The LLMLingua method uses a well-trained language model to identify and remove non-essential tokens in prompts (potentially achieving up to 20x compression with minimal loss).

Improving the Augmentation + Generation Step
Finally, there are some approaches to improving the augmentation + generation of RAG. Here we’ll take a look at some of these methods.
This method involves multiple iterations of the RAG cycle. Taking a look at the diagram below, you can see that each iteration provides slightly different context for the LLM at the generation stage. The goal is to retrieve more relevant knowledge to generate a better response.

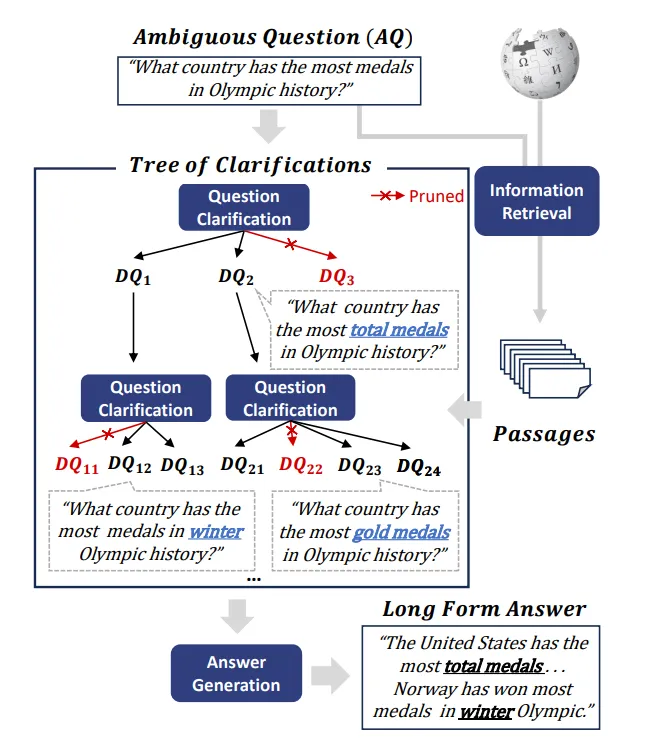
This recursive method helps deal with ambiguities in the query by constructing a tree of ‘uncertanties’ via RAG, and using those results to generate an answer.
In the diagram below, the ambiguous question “What coutnry has the most medals in olympic history” can be “clarified” with different types of medals (bronze, silver, gold). Each question clarification goes through a separate RAG process. Each process is used in the end for a long form answer to answer the ambiguous question.
Evaluation
With so many different approaches to improving your RAG system, how do you decide what to do?
To know which approaches are actually improving your system, you will need to decide on at least one metric. Jason Liu has a post that explains why you would want to use a fast metric over a slow one. Slow metrics are ones that require human input or even AI input. Fast metrics are ones that you can compute quickly, such as accuracy, precision, recall, MRR, and NDCG.

Once you decide on a metric, you can then keep track of how each intervention affects the chosen metric. Of course, the metric still needs to be associated with a business outcome.
Conclusion
RAG is not all you need. By taking a modular approach, you can improve these aspects of RAG with different methods:
- Query
- Retrieval (pre-retrieval, search, post-retrieval)
- Augmentation and Generation
Lastly, it’s useful to choose a fast metric in order to iterate quickly.
Resources
Have some thoughts on this post? Reply with an email.